
Phân biệt biến gây nhiễu (Confounding variable) với biến ngoại lai (Extraneous Variables) trong nhiên cứu thống kê khoa học; Để tìm ra biến gây nhiễu là một việc làm quan trọng giúp cho công việc hồi quy của chúng ta sẽ đạt được kết quả tốt hơn nhiều.
Biến gây nhiễu – Confounding Variable
Biến gây nhiễu là gì ?
Trong nghiên cứu điều tra mối quan hệ nguyên nhân và kết quả tiềm ẩn, một biến gây tạo nhiễu là một biến thứ ba không đo lường được có ảnh hưởng đến cả nguyên nhân được cho là và kết quả được cho là.
Điều quan trọng là phải xem xét các biến tạo nhiễu tiềm ẩn và giải thích chúng trong thiết kế nghiên cứu của bạn để đảm bảo kết quả của bạn là hợp lệ .
Định nghĩa biến nhiễu
Biến gây tạo nhiễu là một biến “ phụ” mà bạn không tính đến. Chúng có thể làm hỏng một cuộc thử nghiệm và mang lại cho bạn những kết quả vô ích. Họ có thể gợi ý rằng có sự tương quan trong khi thực tế là không có. Họ thậm chí có thể giới thiệu sự thiên vị . Đó là lý do tại sao điều quan trọng là phải biết chúng là gì và làm thế nào để tránh đưa chúng vào thử nghiệm của bạn ngay từ đầu.
![[Mở lớp] Phân tích dữ liệu Stata Smartpls Amos R-studio SPSS Minitab NCSS](https://luanvanhay.org/wp-content/uploads/2023/05/huong-dan-6-120x86.jpg)



![[SPSS] Hồi quy đa thức Multinomial Logistic Regression](https://luanvanhay.org/wp-content/uploads/2022/09/dathuc6-FILEminimizer.png)

Cách nhận biết Confounding Variables
Trong một thử nghiệm, biến độc lập thường có ảnh hưởng đến biến phụ thuộc của bạn . Ví dụ: nếu bạn đang nghiên cứu xem liệu thiếu tập thể dục có dẫn đến tăng cân hay không, thì thiếu tập thể dục là biến số độc lập của bạn và tăng cân là biến số phụ thuộc của bạn. Biến gây nhầm lẫn là bất kỳ biến nào khác cũng có ảnh hưởng đến biến phụ thuộc của bạn. Chúng giống như các biến độc lập phụ đang có tác động ẩn lên các biến phụ thuộc của bạn. Các biến gây nhầm lẫn có thể gây ra hai vấn đề lớn:
- Tăng phương sai ( Variance)
- Tạo ra sai lệch / thiên vị (Bias)
Biến nhiễu là gì?
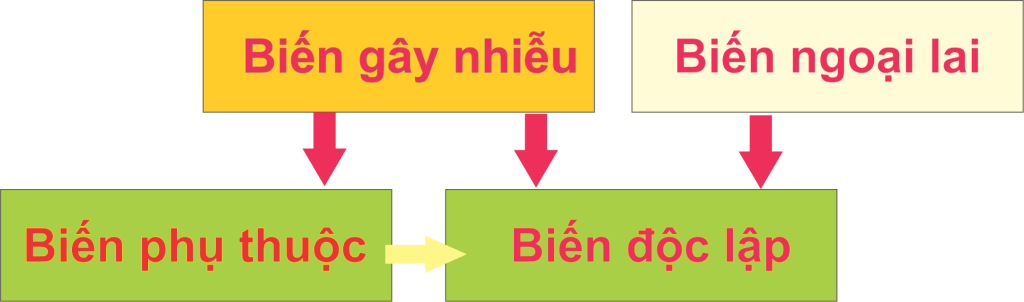
Biến gây nhiễu (hay còn gọi là yếu tố gây nhiễu) là một loại biến ngoại lai có liên quan đến các biến phụ thuộc và độc lập của một nghiên cứu . Một biến phải đáp ứng hai điều kiện để trở thành một yếu tố gây nhiễu:
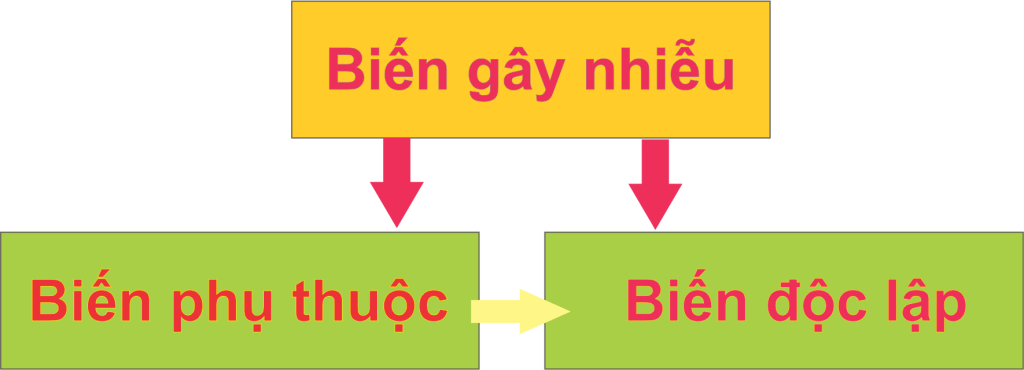
- Nó phải được tương quan với biến độc lập. Đây có thể là mối quan hệ nhân quả, nhưng không nhất thiết phải như vậy.
- Nó phải có quan hệ nhân quả với biến phụ thuộc.
Ví dụ về một biến gây nhiễuBạn thu thập dữ liệu về tình trạng cháy nắng và tiêu thụ kem. Bạn thấy rằng việc tiêu thụ kem nhiều hơn có liên quan đến khả năng bị cháy nắng cao hơn. Điều đó có nghĩa là tiêu thụ kem gây ra cháy nắng?Ở đây, biến số gây nhiễu là nhiệt độ: nhiệt độ nóng khiến mọi người ăn nhiều kem hơn và dành nhiều thời gian hơn ở ngoài trời dưới ánh nắng mặt trời, dẫn đến cháy nắng nhiều hơn.Tại sao các biến tạo nhiễu lại quan trọng
Để đảm bảo giá trị nội bộ của nghiên cứu của bạn, bạn phải tính đến các biến nhiễu. Nếu bạn không làm như vậy, kết quả của bạn có thể không phản ánh mối quan hệ thực tế giữa các biến mà bạn quan tâm ..
Ví dụ: bạn có thể thấy mối quan hệ nguyên nhân và kết quả không thực sự tồn tại, bởi vì tác động mà bạn đo lường được gây ra bởi biến nhiễu (chứ không phải bởi biến độc lập của bạn).
Thí dụBạn thấy rằng nhiều công nhân được tuyển dụng ở các bang có mức lương tối thiểu cao hơn. Điều này có nghĩa là mức lương tối thiểu cao hơn dẫn đến tỷ lệ việc làm cao hơn?
Không cần thiết. Có lẽ các bang có thị trường việc làm tốt hơn có nhiều khả năng tăng lương tối thiểu hơn là ngược lại. Bạn phải xem xét các xu hướng việc làm trước đây trong phân tích của bạn về tác động của mức lương tối thiểu đối với việc làm, hoặc bạn có thể tìm thấy mối quan hệ nhân quả mà không tồn tại.
Ngay cả khi bạn xác định đúng mối quan hệ nguyên nhân và kết quả, các biến gây nhiễu có thể dẫn đến đánh giá quá mức hoặc đánh giá thấp tác động của biến độc lập lên biến phụ thuộc của bạn.
Thí dụBạn thấy rằng những đứa trẻ được sinh ra từ những bà mẹ hút thuốc trong thời kỳ mang thai của họ có cân nặng thấp hơn đáng kể so với những đứa trẻ được sinh ra từ những bà mẹ không hút thuốc. Tuy nhiên, nếu bạn không tính đến thực tế là những người hút thuốc có nhiều khả năng tham gia vào các hành vi không lành mạnh khác, chẳng hạn như uống rượu hoặc ăn những thực phẩm kém lành mạnh hơn, thì bạn có thể đánh giá quá cao mối quan hệ giữa hút thuốc và trẻ nhẹ cân.Cách giảm tác động của các biến gây nhiễu
Có một số phương pháp tính toán các biến nhiễu. Bạn có thể sử dụng các phương pháp sau khi nghiên cứu bất kỳ loại đối tượng nào — con người, động vật, thực vật, hóa chất, v.v. Mỗi phương pháp đều có ưu và nhược điểm riêng.
Sự hạn chế
Trong phương pháp này, bạn hạn chế nhóm điều trị của mình bằng cách chỉ bao gồm các đối tượng có cùng giá trị của các yếu tố gây nhiễu tiềm ẩn.
Vì những giá trị này không khác nhau giữa các đối tượng nghiên cứu của bạn, chúng không thể tương quan với biến độc lập của bạn và do đó không thể làm xáo trộn mối quan hệ nguyên nhân và kết quả mà bạn đang nghiên cứu.
Ví dụ về hạn chếBạn muốn nghiên cứu xem chế độ ăn ít carb có thể làm giảm cân hay không. Vì bạn biết rằng tuổi tác, giới tính, trình độ học vấn và cường độ tập thể dục là tất cả các yếu tố có thể liên quan đến việc giảm cân, cũng như chế độ ăn kiêng mà đối tượng của bạn chọn theo, bạn chọn giới hạn đối tượng của mình ở độ tuổi 45 phụ nữ có bằng cử nhân tập thể dục với cường độ vừa phải từ 100–150 phút mỗi tuần.- Tương đối dễ thực hiện
- Hạn chế mẫu của bạn rất nhiều
- Bạn có thể không xem xét các yếu tố gây nhiễu tiềm ẩn khác
Phù hợp
Trong phương pháp này, bạn chọn một nhóm so sánh phù hợp với nhóm điều trị. Mỗi thành viên của nhóm so sánh nên có một đối chứng trong nhóm điều trị có cùng giá trị của các yếu tố gây nhiễu tiềm ẩn, nhưng các giá trị biến độc lập khác nhau.
Điều này cho phép bạn loại bỏ khả năng sự khác biệt về các biến tạo nhiễu gây ra sự khác biệt về kết quả giữa nhóm điều trị và nhóm so sánh. Do đó, nếu bạn đã tính đến bất kỳ yếu tố gây nhiễu tiềm ẩn nào, bạn có thể kết luận rằng sự khác biệt trong biến độc lập phải là nguyên nhân của sự thay đổi trong biến phụ thuộc.
Ví dụ phù hợpTrong nghiên cứu của bạn về chế độ ăn kiêng low-carb và giảm cân, bạn so sánh các đối tượng của mình về tuổi tác, giới tính, trình độ học vấn và cường độ tập luyện. Điều này cho phép bạn bao gồm nhiều đối tượng hơn: nhóm điều trị của bạn bao gồm nam giới và phụ nữ ở các độ tuổi khác nhau với nhiều trình độ học vấn khác nhau.
Mỗi đối tượng thực hiện chế độ ăn kiêng low-carb sẽ phù hợp với một đối tượng khác có cùng đặc điểm không ăn kiêng. Vì vậy, đối với mỗi người đàn ông 40 tuổi có trình độ học vấn cao theo chế độ ăn kiêng low-carb, bạn sẽ tìm thấy một người đàn ông 40 tuổi khác có trình độ học vấn cao nhưng không, để so sánh mức giảm cân giữa hai đối tượng. Bạn làm tương tự cho tất cả các đối tượng khác trong mẫu điều trị của bạn.
- Cho phép bạn bao gồm nhiều đối tượng hơn là giới hạn
- Có thể chứng minh là khó thực hiện vì bạn cần các cặp đối tượng phù hợp trên mọi biến gây nhiễu tiềm năng
- Các biến khác mà bạn không thể so khớp cũng có thể là các biến gây tạo nhiễu
Kiểm soát thống kê
Nếu bạn đã thu thập dữ liệu, bạn có thể bao gồm các yếu tố gây nhiễu có thể làm biến kiểm soát trong các mô hình hồi quy của mình ; bằng cách này, bạn sẽ kiểm soát được tác động của biến gây nhiễu.
Bất kỳ tác động nào mà biến tạo nhiễu tiềm ẩn có trên biến phụ thuộc sẽ hiển thị trong kết quả của hồi quy và cho phép bạn tách tác động của biến độc lập.
Ví dụ về kiểm soát thống kêSau khi thu thập dữ liệu về chế độ giảm cân và chế độ ăn ít carb từ một loạt người tham gia, trong mô hình hồi quy của bạn, bạn bao gồm mức độ tập thể dục, trình độ học vấn, tuổi tác và giới tính làm biến kiểm soát, cùng với loại chế độ ăn uống mà mỗi đối tượng tuân theo là biến độc lập . Điều này cho phép bạn tách tác động của chế độ ăn kiêng đã chọn khỏi ảnh hưởng của bốn biến số khác này đối với việc giảm cân trong hồi quy của bạn.- Dễ để thực hiện
- Có thể được thực hiện sau khi thu thập dữ liệu
- Bạn chỉ có thể kiểm soát các biến mà bạn quan sát trực tiếp, nhưng các biến gây nhiễu khác mà bạn chưa tính đến có thể vẫn còn
Ngẫu nhiên hóa
Một cách khác để giảm thiểu tác động của các biến gây nhiễu là ngẫu nhiên hóa các giá trị của biến độc lập của bạn. Ví dụ: nếu một số người tham gia của bạn được chỉ định vào một nhóm điều trị trong khi những người khác thuộc nhóm đối chứng , bạn có thể chỉ định ngẫu nhiên những người tham gia vào mỗi nhóm.
Việc ngẫu nhiên hóa đảm bảo rằng với một mẫu đủ lớn, tất cả các biến gây phát nhiễu tiềm ẩn — ngay cả những biến mà bạn không thể quan sát trực tiếp trong nghiên cứu của mình — sẽ có cùng giá trị trung bình giữa các nhóm khác nhau. Vì các biến này không khác nhau theo cách phân công nhóm, chúng không thể tương quan với biến độc lập của bạn và do đó không thể làm xáo trộn nghiên cứu của bạn.
Vì phương pháp này cho phép bạn tính đến tất cả các biến gây nhiễu tiềm ẩn, điều này gần như không thể làm được, nên nó thường được coi là cách tốt nhất để giảm tác động của các biến gây nhiễu.
Ví dụ về ngẫu nhiên hóaBạn tập hợp một nhóm lớn các đối tượng để tham gia vào nghiên cứu của bạn về giảm cân. Bạn chọn ngẫu nhiên một nửa trong số họ theo chế độ ăn kiêng low-carb và nửa còn lại tiếp tục thói quen ăn uống bình thường.
Việc ngẫu nhiên hóa đảm bảo rằng cả phương pháp điều trị của bạn (nhóm ăn kiêng low-carb) cũng như nhóm đối chứng của bạn sẽ không chỉ có cùng độ tuổi trung bình, trình độ học vấn và mức độ tập thể dục mà còn có cùng giá trị trung bình về các đặc điểm khác mà bạn chưa đo lường cũng.
- Cho phép bạn tính đến tất cả các biến có thể gây nhiễu, bao gồm cả những biến mà bạn có thể không quan sát trực tiếp
- Được coi là phương pháp tốt nhất để giảm thiểu tác động của các biến gây phát nhiễu
- Khó thực hiện nhất
- Phải được triển khai trước khi bắt đầu thu thập dữ liệu
- Bạn phải đảm bảo rằng chỉ những người trong nhóm điều trị (chứ không phải nhóm kiểm soát) mới được điều trị
![[Mở lớp] Phân tích dữ liệu Stata Smartpls Amos R-studio SPSS Minitab NCSS](https://luanvanhay.org/wp-content/uploads/2023/05/huong-dan-6-360x180.jpg)








{kind=link}