
Phân tích lớp tiềm ẩn LCA Latent Class Analysis, dịch vụ chạy ứng dụng mô hình kinh tế lượng theo yêu cầu của khách hàng, chỉnh sửa số liệu cho có ý nghĩa thống kê, hướng dẫn chạy trên các phần mềm kinh tế lượng thông dụng như: R, Stata, Eviews, Minitab, Spss …
PHÂN TÍCH LỚP TIỀM ẨN
LCA
Latent Class Analysis
Mô hình Phân tích lớp tiềm ẩn LCA là gì ?
Trong thống kê , một mô hình lớp tiềm ẩn ( LCM ) liên quan đến một tập hợp các biến đa biến quan sát (thường là rời rạc) với một tập hợp các biến tiềm ẩn . Nó là một loại mô hình biến tiềm ẩn . Nó được gọi là mô hình lớp tiềm ẩn vì biến tiềm ẩn là rời rạc. Một lớp được đặc trưng bởi một mẫu các xác suất có điều kiện chỉ ra cơ hội mà các biến có các giá trị nhất định.
Phân tích lớp tiềm ẩn ( LCA ) là một tập hợp con của mô hình phương trình cấu trúc , được sử dụng để tìm các nhóm hoặc các kiểu con của các trường hợp trong dữ liệu phân loại đa biến. Những kiểu con này được gọi là “các lớp tiềm ẩn”.
Đối mặt với một tình huống như sau, một nhà nghiên cứu có thể chọn sử dụng LCA để hiểu dữ liệu: Hãy tưởng tượng rằng các triệu chứng quảng cáo đã được đo ở một loạt bệnh nhân mắc bệnh XY và Z, và bệnh X có liên quan đến sự hiện diện của các triệu chứng a, b, và c, bệnh Y với các triệu chứng b, c, d và bệnh Z với các triệu chứng a, c và d.






LCA sẽ cố gắng phát hiện sự hiện diện của các lớp tiềm ẩn (các thực thể gây bệnh), tạo ra các mô hình liên kết trong các triệu chứng. Như trong phân tích nhân tố, LCA cũng có thể được sử dụng để phân loại trường hợp theo khả năng thành viên nhóm tối đa của họ .
Bởi vì tiêu chí để giải quyết LCA là đạt được các lớp tiềm ẩn trong đó không còn mối liên hệ nào giữa triệu chứng này với triệu chứng khác (vì lớp này là căn bệnh gây ra mối liên hệ của họ) và tập hợp các bệnh mà bệnh nhân mắc phải (hoặc lớp a trường hợp là thành viên của) gây ra sự liên quan đến triệu chứng, các triệu chứng sẽ “độc lập có điều kiện”, nghĩa là có điều kiện về tư cách thành viên của lớp, chúng không còn liên quan.
Lý thuyết về Latent Class Analysis (LCA)
LCA là viết tắt của Latent Class Analysis, có thể hiểu là phân tích lớp tiềm ẩn. Phân tích lớp tiềm ẩn là phân tích các nhóm không10 quan sát được có trong tập dữ liệu. Giả sử, một cửa hàng có một tập dữ liệu của các khách hàng và chủ cửa hàng tin rằng cách khách hàng này có thể chia thành 3 nhóm dựa vào sự quan tâm tiềm năng về sản phẩm của cửa hàng. Tuy nhiên, trong tập dữ liệu của cửa hàng không có biến xác định mỗi khách hàng thuộc nhóm nào.
Tổng quát hơn, có nhiều nhóm khác nhau trong tổng thể và các cá nhân trong mỗi nhóm sẽ cư xử một cách khác nhau. Nhưng không có một biến nào xác định các nhóm. Các nhóm ở đây có thể là người tiêu dùng với các sỏ thích mua sắm khác nhau, hoặc các thanh thiếu niên với lối sống khác nhau… Phương pháp phân tích lớp tiềm ẩn sẽ xác định và phân loại những nhóm này. Nó cho biết cá nhân nào thuộc nhóm nào và đặc điểm của một nhóm sẽ nhận biết với nhóm khác như thế nào.
Trong phân tích lớp tiềm ẩn sẽ sử dụng một biến danh mục để ghi nhận các nhóm. Các mô hình phân tích lớp tiềm ẩn sẽ gồm hai phần là (i) tính toán xác suất mà mỗi cá nhân thuộc về một nhóm; (ii) mô tả mối quan hệ giữa các nhóm với các biến được quan sát. Các biến được quan sát ở đây có thể ở dạng nhị phân, thứ tự hoặc biến liên tục. Sau khi ước lượng mô hình, tính toán xác suất một cá nhân thuộc về một nhóm hoặc tính toán giá trị biên trung bình của các biến quan sát trong mỗi nhóm ẩn.
Thực hành Phân tích lớp tiềm ẩn trong STATA
Trước tiên chúng ta sử dụng bộ dữ liệu sau:
use http://solieu.vip/data/usmacro.dta
Để tìm hiểu chỉ số ogap và lạm phát inflation ảnh hưởng đến quỹ tín dụng fedfund. Để tìm hiểu về mối quan hệ này, chúng ta đã sử dụng nhiều mô hình kinh tế lượng như hồi quy bình phương nhỏ nhất, hay hồi quy ngưỡng để xác nhận các mối quan hệ xảy ra.
Trong trường hơp này chúng ta sẽ phân quỹ tín dụng fedfund ra thành 2 lớp, để xem các lớp đó có ảnh hưởng khác nhau đến mối quan hệ chung cuộc hay không ?
Chúng ta cấu hình mô hình như trong hình vẽ:
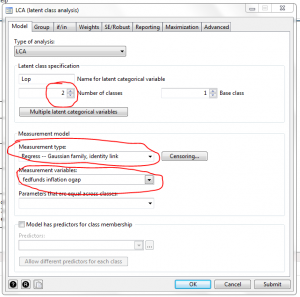
hay sử dụng câu lệnh:
gsem (fedfunds inflation ogap <- _cons), family(gaussian) link(identity) lclass(Lop 2)
Ta được kết quả của hồi quy phân lớp điều có ý nghĩa thống kê, như sau:
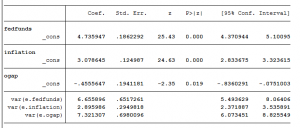
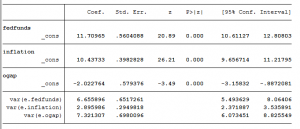
Kiểm định LCA Phân tích lớp tiềm ẩn
Như đã thấy được kết quả phân tích lớp tiềm ẩn như trên, để sử dụng kết quả ấy chúng ta cần làm vài thao tác kiêm định cần thiết để sử dụng được kết quả này:
Kiểm định sự phù hợp của mô hình Goodness of fit
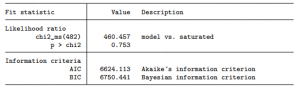
Kết quả của Kiểm định Goodness of fit cho ta thấy rằng sự phân lớp là hơp lý.
Độ nhạy biên của mô hình
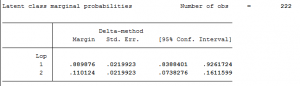
Kết quả chạy độ nhạy biên cho ta thấy rằng, Lớp 1 có ảnh hưởng đến 89% kết quả hồi quy. Còn lớp 2 chỉ ảnh hưởng có 11%.
Phương pháp nghiên cứu LCA Phân tích lớp tiềm ẩn
Có một số phương thức với các tên riêng biệt và cách sử dụng có chung mối quan hệ. Phân tích cụm , giống như LCA, được sử dụng để khám phá các nhóm trường hợp giống như taxon trong dữ liệu. Ước tính hỗn hợp đa biến (MME) có thể áp dụng cho dữ liệu liên tục và giả định rằng dữ liệu đó phát sinh từ hỗn hợp phân phối: hãy tưởng tượng một tập hợp chiều cao phát sinh từ hỗn hợp nam và nữ. Nếu ước tính hỗn hợp đa biến bị hạn chế để các biện pháp phải được hủy bỏ trong mỗi phân phối thì nó được gọi là phân tích hồ sơ tiềm ẩn. Được sửa đổi để xử lý dữ liệu rời rạc, phân tích bị ràng buộc này được gọi là LCA. Các mô hình đặc điểm tiềm ẩn riêng biệt tiếp tục ràng buộc các lớp hình thành từ các phân đoạn của một chiều: về cơ bản phân bổ các thành viên cho các lớp trên chiều đó: một ví dụ sẽ gán các trường hợp cho các lớp xã hội theo chiều hướng khả năng hoặc giá trị.
Như một ví dụ thực tế, các biến có thể là các mục nhiều lựa chọn của một câu hỏi chính trị. Dữ liệu trong trường hợp này bao gồm bảng dự phòng N-way với câu trả lời cho các mục cho một số người trả lời. Trong ví dụ này, biến tiềm ẩn đề cập đến ý kiến chính trị và các lớp tiềm ẩn cho các nhóm chính trị. Với tư cách thành viên nhóm, xác suất có điều kiện xác định cơ hội câu trả lời nhất định được chọn.






![[Mở lớp] Phân tích dữ liệu Stata Smartpls Amos R-studio SPSS Minitab NCSS](https://luanvanhay.org/wp-content/uploads/2023/05/huong-dan-6-120x86.jpg)



{kind=link}