
Hướng dẫn hồi quy nhị phân binary logistic trên spss, với hồi quy này ta có thể dễ dàng để thực hiện trên các phần mềm thống kê khác như r, stata, eviews … trong ví dụ này để cho dễ hiểu vì phần đông sinh viên được học thống kê trên phần mềm spss. Nên tác giả chọn phần mềm này.
HƯỚNG DẪN HỒI QUY NHỊ PHÂN BINARY LOGISTIC
Trong bài viết dụ này ngoài chạy mô hình hồi quy; nhằm đảm bảo khả năng tin cậy chúng ta cần phải thực hiện hai kiểm định: Tương quan từng thành phần của các hệ số hồi quy và mức độ phù hợp của mô hình. Trước khi tiếp tục tìm hiểu về phương pháp, cách đọc dữ liệu kết quả, chúng ta hãy xem xét xem mô hình hồi quy nhị phân binary logistic là gì ?

HOT:






Mô hình nhị phân Binary Logistic là gì ?
Trong thống kê , mô hình logistic (hoặc mô hình logit ) là một mô hình thống kê được sử dụng rộng rãi , trong dạng cơ bản của nó, sử dụng một hàm hậu cần để mô hình biến phụ thuộc nhị phân ; nhiều phần mở rộng phức tạp hơn tồn tại. Trong phân tích hồi quy , hồi quy logistic (hoặc hồi quy logit ) đang ước tính các tham số của một mô hình hậu cần; nó là một dạng hồi qui nhị thức. Về mặt toán học, một mô hình logistic nhị phân có một biến phụ thuộc với hai giá trị có thể, chẳng hạn như pass / fail, win / loss, alive / dead hoặc healthy / sick; chúng được biểu diễn bằng một biến chỉ thị , trong đó hai giá trị được gắn nhãn “0” và “1”. Trong mô hình logistic, tỷ lệ log-log ( logarit của tỷ lệ cược ) cho giá trị có nhãn “1” là sự kết hợp tuyến tính của một hoặc nhiều biến độc lập (“dự báo”); các biến độc lập có thể là biến nhị phân (hai lớp, được mã hóa bởi một biến chỉ thị) hoặc một biến liên tục (bất kỳ giá trị thực nào). Xác suất tương ứngcủa giá trị có nhãn “1” có thể khác nhau giữa 0 (chắc chắn là giá trị “0”) và 1 (chắc chắn là giá trị “1”), do đó ghi nhãn; hàm chuyển đổi tỷ lệ chênh lệch log thành xác suất là hàm logistic, do đó tên. Các đơn vị đo lường cho quy mô log-tỷ lệ cược được gọi là một logit , từ log un istic nó , vì thế mà cái tên thay thế. Các mô hình tương tự với một hàm sigmoid khác thay vì hàm hậu cần cũng có thể được sử dụng, chẳng hạn như mô hình probit ; đặc tính xác định của mô hình hậu cần là việc tăng một trong các biến độc lập nhân với tỷ lệ chênh lệch của kết quả đã cho tại một hằng sốtỷ lệ, với mỗi biến phụ thuộc có tham số riêng; đối với biến độc lập nhị phân, điều này sẽ tổng quát tỷ lệ chênh lệch .
Xem hết định nghĩa thì chúng ta cũng ” chóng mặt” chỉ cần nhớ cho tác giả, nó giống như hồi quy đa biến bình thường, như biến phụ thuộc chỉ nhận hai giá trị: 0/1, co/không, bị/không bị ….
Ví dụ đưa ra
Trong file đính kèm, là mô hình : Các yếu tố ảnh hưởng đến Quyết định mua bảo hiểm y tế tại tỉnh X. Lúc này biến phụ thuộc sẽ là biến quyết định trong bài ký hiệu là QDINH nhận 2 giá trị 0: không mua, 1 có mua. Còn lại là các biến độc lập và có tác động đến mô hình. như: Giới tính, hôn nhân, thất nghiệp, học vấn ….
(Nói lại: Vì bài này là hướng dẫn sử dụng mô hình logit trên spss, không phải là phân tích mô hình : các nhân tố ảnh hưởn đến quyết định ….. Các bạn nên nhớ.)
Chạymô hình trên spss
Ta kích hoạt chương trình theo lệnh sau: Analyse > regression > Binary Logistic
Ta đưa biến phụ thuộc QDINH vào ô : Dependent
Còn các biến độc lập đưa vào ô: Covariates
Như trong hình sau:
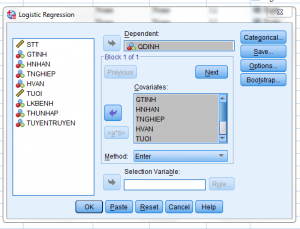
Trong mục “Save” ta check như hình :
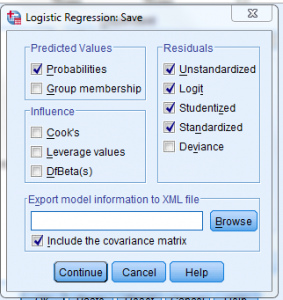
Bấm ” Continue” và Chọn “OK” ta được kết quả.
Sau khi đã ra kết quả chúng ta cần các kiểm định để cho mô hình có độ tin cậy – nói chung là xài được.
1 Kiểm định hệ số hồi quy
Trong kiểm định này ta sử dụng kiểm dịnh Wald để kiểm tra xem các biến độc lập có ảnh hưởng tới biến phụ thuộc hay nói cách khác hay nói cách khác các biến tương quan có ý nghĩa với biến phụ thuộc QDINH hay không ?
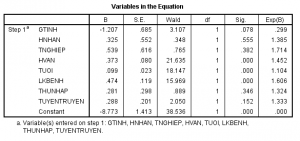
Ta chú ý vào cột Sig, ta xét giá trị sig này với mức ý nghĩa 5%, nếu sig >= 0.05 thì ta loại biến, và ngược lại. Trong ví dụ này tôi sẽ làm 2 biến ví dụ thôi, chứ làm hết 8 biến thì cũng như vậy thôi.
Ta có Biến TNGHIEP có sig = 0.382 và nó thì > 0.05. Do đó, biến TNGHIEP tương quan không có ý nghĩa với biến QDINH.
Giải thích theo kiểu dân dã: Do có thất nghiệp hay không, thì quyết định mua bảo hiểm y tế không ảnh hưởng gì, ta có thể mở rộng, khoảng tiền bảo hiểm y tế không cao nên nó phụ hợp với nhiều người, ngay cả những người thất nghiệp ( thất nghiệp ở VN là những người làm lao động phổ thông, công việc không ổn đinh….) tôi lại lan man qua phần phân tích mô hình rồi. D:
Tiếp, ta xét biến HVAN có sig= 0.00 và nó thì < 0.005. Do đó, biến HVAN tương quan có ý nghĩa với biến QDINH với độ tin cậy 95%
Các bạn làm tương tự cho các biến độc lập tiếp theo
Như vậy mô hình chỉ còn 3 biến là: HVAN, TUOI, LKBENH là có ý nhĩa thống kê.
2. Kiểm định mức độ phù hợp của mô hình
a. Mức độ dự báo chính xác
ta xem bảng kết quả sau:
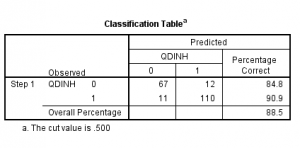
Theo kết quả: Những người không mua là 78 người trong đó mô hình dự báo đúng là 67 người nên ta có tỉ lệ dự báo chính xác là 84,8 % và những người mua là 122 người trong đó mô hình dự báo đúng là 110 tức chiếm 90.9%. Và mô hình chúng ta dự báo chính xác là 88.5% ( Mô hình chỉ cần trên 50% là chấp nhận được, còn bên sức khỏe thì cần phải cao hơn).
b. Mức độ phù hợp của mô hình
ta xét bảng tiếp
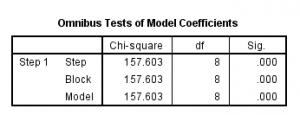
Ta xét kiểm định Omnibus, ta xét sig của model là 0.00 , nó < 0.01 ( với độ tin cậy 99%). Như vậy các biến độ lập có quan hệ tuyến tính với biến phụ thuộc trong tổng thể. Nói cách khác, mô hình lựa chọn là phù hợp.
Kết luận, như vậy là mô hình của chúng ta chỉ sử dụng 3 biến độc lập như phần trên là có ý nghĩa thống kê. Ta dùng 3 biến này vào phần thảo luận kết quả hồi quy logit.
Trong bài này LuanVanHay.Org chỉ hướng dẫn các bạn chạy mô hình logit trên spss và sử dụng các kiểm định cho mô hình, phần thảo luận kết quả hồi quy sẽ trình bày trong bài sau.
Cảm ơn các bạn đã đọc và phản hồi.
Thân ái.
P/S: Hướng dẫn hồi quy mô hinh tobit trên stata






![[Mở lớp] Phân tích dữ liệu Stata Smartpls Amos R-studio SPSS Minitab NCSS](https://luanvanhay.org/wp-content/uploads/2023/05/huong-dan-6-120x86.jpg)



{kind=link}